
 刘通
刘通
在数字化转型中,需要通过各个渠道将散步在企业中的数据获取到数据存储载体,对这些数据进行统一、集中的管理,分析与价值挖掘,以及后续的场景化运用。那么,这些宝贵的数据应该从哪里来呢?企业应当如何高效地从业务中获取数据资源,数字化企业究竟有哪些主要的技术手段可以采用?
企业获取数据有两个主要渠道,一是从业务环境中主动获取数据,这种方式称为数据感知;二是从业务系统中对软件应用产生的数据进行自动采集,这种方式称为数据同步。下面分别进行介绍:
1.数据感知
数据感知是指直接从业务环境中采集并获取数据,本质上是一种主动获取数据的技术手段,数据感知直接服务于数据分析的需求。具体来看,数据感知又包括硬感知和软感知两种基本形式。其中,数据硬感知是指采用特定的数据采集设备从物理世界中进行数据的收集,数据软感知是指从虚拟的数字世界中进行数据收集。
(1)数据硬感知
参考华为的数据治理框架,数据硬感知技术包括身份数据采集、文字数据采集、图像数据采集、音频数据采集、视频数据采集、传感器数据采集等几个方面:
身份数据采集是指通过外部设备对身份标签进行扫描,快速识别物理环境中的业务主体,实现业务主体的过程跟踪:条码是一种十分常见的数据表示方式,经常被用来记录关于产品或原料的基本信息,通过扫码枪对条码进行近距离扫描,可以在特定的业务环节快速记录并跟踪产品的实时状态;射频识别技术(Radio-frequency Identification,RFID)的原理与条码标签类似,但其不受光线环境干扰,数据的读取过程高度并发的,同时支持对标签中的数据反复修改;近距离无线通讯技术(Near Field Communication,NFC)是出于对特别应用场景的要求在RFID基础上衍生出的通讯技术,其数据传输比RFID具有更强安全性。
文字数据采集主要解决非数字原生企业将传统纸质媒介的数据资料以自动化的方式转录到电子文件中,降低人工抄录文字产生的高昂成本。文字数据采集的常用的方式是OCR(Optical Character Recognition,光学字符识别)技术,该技术采用深度学习模型,模型的输入是图片,输出是文字,快速地识别图片中的文字信息。例如,某企业需要把纸质的产品名录快速录入到数据库中,对产品的文字材料进行拍照,使用OCR软件批量地将纸质页照片信息转变为可编辑的计算机字符的格式。
图像数据采集是指通过传感器对特定业务对象捕捉后,提取其中的该对象的图像特征,同时与预先存储的图像模板进行匹配,从而实现特定业务对象的识别和存储。围绕图像识别技术所针对的目标对象类型,图像识别技术具体又包括人脸识别、指纹识别、虹膜识别、商品识别等各种细分的技术落地场景。
音频数据可以通过麦克风的音频录入设备直接记录原始的声音信息获得,也可以通过所下载的MP3文件以及CD等存储介质中获取音频数据,并以二进制的形式进行存储。音频数据采集后,通常需要对音频文件中的人类语音进行自动识别和提取,将其转化为可以被人或机器进行理解的文本格式进行存储和管理。
对于视频数据的获取,企业可以从开源网络渠道下载已经完成录入的视频文件,从VCD、DVD等存储设备中获取复制截取视频文件,或直接使用摄像设备从外界业务场景中采集一手的视频信息。数据收集来说,主要是通过摄像设备将光源信号采集并转化为电信号,当前使用的图像传感技术主要为CCD和CMOS两种技术系统。
传感器是把物理世界中的信息转变为数字世界信息的各种设备统称,可以将企业所关注的业务环境信息进行准确、客观的量化,将采集到的状态信息按照一定的规律进行表示。传感器采集的数据具有数据类型多样、时序性、实时性、过程性、具有较大噪音和干扰、数据规模大、数据价值密度低等诸多方面特点。
(2)数据软感知
数据软感知技术是指在数字世界内部的数据采集过程,与硬感知技术不同,被采集的数据本身也存在于数字世界。参考华为的数据治理框架,数据软感知技术包括埋点、日志数据采集等主要形式。
埋点是用来收集用户浏览网页、使用APP等在线行为数据的方法,这些行为数据对于软件平台的运营者和产品经理来说具有非常大的参考价值。埋点的本质是一段代码,通过将这段代码潜入到应用程序中,可以对软件程序的特定“事件”进行“响应”。软件程序的事件是通过用户的使用行为触发产生的,对软件程序事件的记录等价于对用户在线行为的采集,典型事件包括点击事件、曝光事件、内容浏览事件等。当前,常见的埋点技术策略主要包括代码埋点、可视化埋点,以及全埋点三种方式。
日志采集的目的是自动记录计算机设备的运行历史情况,用户系统运维、信息活动审计,以及数据安全管理。单机场景下日志数据采集的方式相对容易,可以通过简单的代码轻松完成日志数据的打印和存储工作。企业级应用中,日志采集对象更多为分布式场景,即日志数据产生于不同的计算机设备上。日志采集方法主要有:传统文件方式、基于数据库的读写交互方式,以及基于消息队列的日志采集系统等。
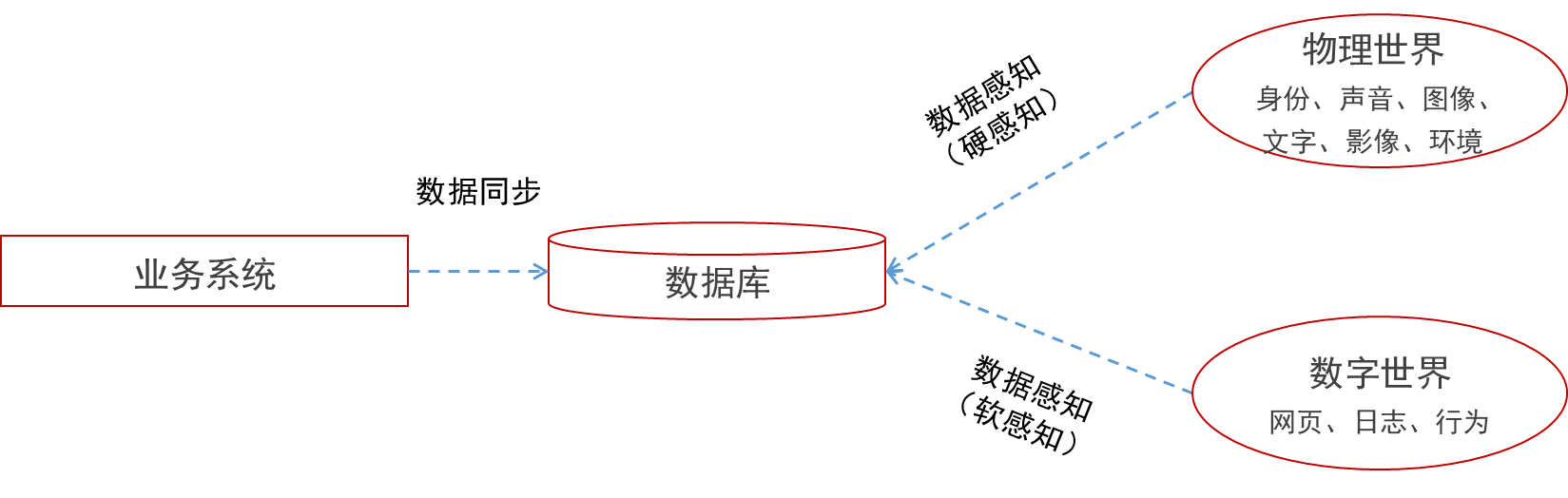
图20. 数据获取的主要技术手段
2.数据同步
对于数字化应用来说,业务系统中的数据无法直接进行价值挖掘和应用,必须将生产数据“复制”出来,“搬运”到离线环境中才可以进行后续的分析处理。为了对内部数据进行分析,就需要通过数据同步的方式,把生产数据转化为离线数据。例如,将业务系统中的数据库中的数据,自动同步到数据中台的数据存储区域。对数据进行同步的方式包括关系型数据库收集和非关系数据收集两部分内容。
(1)关系型数据库收集
关系型数据库收集是指数据中台从前端诸多业务系统中的关系型数据表进行数据的收集和同步,是针对传统事务数据同步的典型场景。当前,针对关系型数据库收集主要有直连同步和日志解析两种主要技术策略。
直连同步(全量同步)的方法实现逻辑比较简单,通过定义好的数据服务API接口(如ODBC、JDBC等)直连访问数据源,对数据进行SELECT操作,将查询到的数据存储到本地文件,最后再把查询结果文件加载到数据中台的目标位置。直连同步的问题在于,随着业务规模的增长,数据同步花费的时间会很长,同时直接对数据源端进行大规模数据量的访问,会影响业务系统在主业务中的正常使用。基于直连同步策略的数据库收集工具主要有DataX、Sqoop等。
日志解析(增量同步)的方法可以回避直连同步方式的若干技术缺陷。通过捕捉数据库的变更日志(CDC,Change Data Capture),如MySQL的BinLog日志,动态地对发生变化的数据对象进行发现和解析,实现数据实时或准实时的同步效果。基于这种方式的增量数据同步,数据更新的延迟甚至可以被控制在毫秒级别。日志解析的数据收集过程是在操作系统层面完成的,不需要通过数据库,因此不会给数据源所在的业务系统产生影响。基于日志解析策略的数据库收集工具主要有Maxwell、Canal等。
(2)非关系型数据库收集
非关系数据的收集更多在于对流数据的实时同步场景。日志是一种非常重要的非结构化数据资源,业务系统每秒都会以数据流的形式产生大量的日志数据。Flume是面向该数据同步场景的重要技术引擎,是由Cloudera开发的一套面向流式数据源的日志收集系统,可以解决企业对非关系数据收集的不同定制化需求。
Flume可以从运行在不同机器上的服务中对日志数据进行自动收集,将其同步到HDFS或HBase的数据存储上。Flume采用了插拔式的软件架构,所有技术组件都可以进行灵活配置。Flume屏蔽了前端流式数据源和后端中心化数据存储之间的异构型特征,可以支持从控制台(Console)、RPC、text文件、UNIX tail、syslog、exec等各种类型的数据源渠道进行日志采集的技术任务。

