
 刘通
刘通
数字化转型的核心是对数据资源的应用,那么,企业的数据资源到底是存储在哪里的呢?在数字化建设中,提到对数据资源的访问和使用,通常会涉及到很多和数据存储载体相关的技术概念,比如数据库、数据仓库、数据湖,以及数据中台等,下面将对这些存储数据的技术概念进行区分性的介绍:
1.数据库
数据库是存储数据的技术载体统称,这个概念强调的是能够按照一定组织形式,对数据进行集中存储和管理的功能特点。几乎任何需要对数据进行访问和处理的信息系统,都需要有数据库构成组件。从软件工程的视角来说,数据库一般与数据库管理系统(DBMS,Database Management System)一起使用,数据库管理系统是一种操纵和管理数据库的大型应用软件,用于建立、使用和维护数据库。
任何软件系统或者应用程序,都必须通过数据库管理系统才能访问和使用数据库种的数据资源,因此,在很多技术需求讨论时,并不强行对数据库和数据库管理系统进行刻意的区分。面向功能特性和使用场景,数据库有很多种不同的分类。
面向功能特性,数据库主要包括,传统的关系型数据库和非关系型数据库(NoSQL)。传统的关系型数据库遵循SQL数据库语言标准,主要面向结构化表格数据进行查询和操作。在信息化时代,绝大部分的信息系统都针对结构化数据进行处理。因此,关系型数据库在信息化时代是主流的数据库选型。常见的关系型数据库有SQL Server、MySQL、Oracle等。
和关系型数据库相比,NoSQL不保证关系型数据库的ACID(原子性、一致性、隔离性、持久性)特征,对数据对象的组织形式更加灵活,更易扩展,更加适合大数据时代的数据分析与应用需求。NoSQL数据库并没有统一的标准,是一系列特殊功能特点的数据库的统称,常见的NoSQL有键值(Key-Value)数据库、列存储数据库、文档型数据库、图形数据库,以及时间序列数据库等:
键值数据库的特点是通过Hash的方式实现快速数据查找,主要用于对大数据内容的缓存,处理对数据资源的高访问负载,其优点是高效的查询效率。常见的键值数据库有Redis、Voldemort、Oracle BDB等;
列存储数据库的特点是将同一列的数据内容存储在一切,这样的数据组织形式可以更好地进行数据量的扩展,查询速度更快,同时有利于在分布式架构上存储数据资源。常见的列存储数据库有Cassandra、HBase、Riak等;
文档型数据库的底层也是Key-Value的结构,但是与键值数据库不同在于,文档数据库不仅可以通过Key查询到Value,还可以将Value看作一个结构化的文档对象,文档对象内部的属性信息是透明的,可以直接被查询到。通过文档的表示形式,可以灵活地定义各种复杂数据结构并存储相关信息。常见的文档数据库包括MongoDB、CouchDB等;
图形数据库主要用于存储网络结构的数据对象,对图数据的查询和计算分析具有很好的支持性。与传统的结构化数据相比,图数据包含“高阶”的数据对象关系,传统的关系型数据库难以对这种复杂关系进行有效的识别处理,而图数据库的数据组织形式恰恰弥补了这方面的不足。常见的图数据库包括Neo4J、Galaxybase等。
面向使用场景,数据库可以分为事务型数据库和分析型数据库。事务型数据库主要面向企业的OLTP需求,通过业务信息系统实现业务活动的在线化、流程化、自动化;分析型数据库主要面向企业的OLAP需求,通过各种类型的数据分析平台,为用户提供交互式的数据分析能力。
事务型数据库的技术性能要求是符合ACID性质,因此在数据库的选型方面限制较多,事务型数据库一般选择关系模型进行数据建模;分析型数据库的技术性能要求是快速的查询能力以及可扩展的存储能力,数据库选型上更加灵活,对于结构化数据,分析型数据库一般选择维度模型进行数据建模。此外,分析型数据库和数据仓库的关系更加密切,下面将对数据仓库的概念进行介绍。
2.数据仓库
数据仓库(DW,Data Warehouse)的作用主要是解决企业中各种数据分析需求,是一种建立在数据应用价值方面的数据存储载体。数据仓库是单个数据存储,出于分析性报告和决策支持目的而创建,为企业构建数字化、智能化解决方案提供有效的数据资源支撑。在数字化转型工作中,数据的价值通过数据分析方法来实现,因此可以认为,数据仓库是数字化转型中非常重要的数据资源载体。数据仓库具有以下几个重要特征:
一是数据仓库是面向主题的:
在对企业中的数据进行组织存储时,考虑到数据需要解决分析类的需求,一般将数据按照主题的维度进行划分。例如,在银行、保险及证券等行业领域中,可以将数据对象在数据仓库中按照当事人、市场营销、银行、协议、产品与服务、渠道、资产、财务风险、事件,和地理区域等不同主题进行数据表的设计和数据存储;再例如,在电商平台相关的行业领域中,数据仓库的主题结构可以设计为交易、财务、物流、产品、营销、渠道等。在数据仓库中,数据建模一般采用维度模型,从而更好地支撑OLAP需求以及数据驱动的数字化服务。
二是数据仓库是信息集成的:
数据仓库中的数据来源于“源端”业务系统的事务型数据库。事务型数据库的数据记录是按照流程进行组织划分的。这些数据需要基于维度模型重新进行组织和转换,然后再重新记录在数据仓库的存储介质上。换句话说,数据仓库是对不同业务系统中数据库的统一信息集成,在数据集成的过程中,需要有效地对分析主题进行科学定义和标准化设计。数据仓库的构建基础是信息共享和统一信息建模,其中存储的数据资源可以看作企业重要的信息资产,为前端不同的智能分析与自动事务场景进行赋能;
三是数据仓库是加工汇总的:
数据仓库中的数据并非原始的数据,是对数据源经过加工处理后的结果。数据仓库中的数据表是原始数据经过结构化的加工、处理后的表示形式,在数据加工过程中引入了数据架构师、数据分析人员、业务专家对数据资源的业务认知和系统理解。数据仓库中的数据具有信息价值属性,具有业务应用导向性。
从原始的数据源内容到数据仓库中的数据表,除了要发生数据格式、数据结构方面的转化,还可能涉及到数据挖掘与数据特征抽取等更复杂的预处理操作。例如,原始的数据为非结构化的文本格式,但是用户很难直接对文本数据进行结构化的查询和分析,因此,在技术常见的作法时,通过自然语言处理的算法,从文本中提前抽取出具有业务含义的结构化数据特征,在数据仓库中对结构化特征进行存储。
3.数据湖
数据仓库中的数据,从原始数据源到目标数据存储介质,要经过ETL的过程,即Extraction(抽取)、Transform(转化)、Load(加载)。整个过程数据经过了两个重要的活动变化,一是复制,在数据源对数据进行复制,另外存一份;二是处理,原始数据内容加工处理时发生了内容上的变化,其目的是让数据的信息价值显现。然而,数据从数据源到数据仓库的过程中,数据内容的变化会导致数据项不在那么“原汁原味”,数据的变化过程融合了数据分析人员对业务的主观理解。
通过构建数据仓库进行数据资源整合的方式,其中一个比较明显的缺陷是会导致对数据资源的使用灵活性降低。一方面,数据仓库中转化后的数据表内容质量受限于数据分析人员对业务的理解和认知;另一方面,由于数据仓库中的数据已经是被压缩、筛选过的结果,当外部需求发生变化时,或者业务场景有调整时,还需要重新从“源端”进行数据的采集和处理,数据需求处理效率较低。
针对以上问题,有人提出了一个比较合理的数据管理方式,即先对数据源进行集中备份和存储,该过程中不“预先”对数据进行加工处理,而是在后面使用数据的时候再对数据进行加工。这种策略下形成的数据存储结构叫做“数据湖”(Data Lake)。数据从数据源到数据湖的内容同步方式为ELT(抽取、加载、转化的顺序),“数据再前,模式在后”的数据链路流转策略。
在数据湖中,数据几乎以最原始的方式进行存储。数据湖可以存储不同数据结构的数据内容,既包括结构化数据表格,也包括图数据、时序数据、地图数据,以及文本、音频、图像、视频等非结构化数据或文件数据。数据湖可以对这些不同来源、不同格式的数据提供统一的存储和管理,实现企业中数据资源的全量汇集与价值共享,为各类前端数字化应用提供核心的数据源基础。
当前,一种称为“湖仓一体化”的新型技术架构在解决企业的大数据需求方面变得非常流行。该架构打通了数据仓库和数据湖两种核心的数据存储,将数据仓库的高性能及管理能力和数据湖的灵活性进行了有机融合,“湖仓一体”底层支持多种数据类型并存,上层则能基于统一封装的接口进行数据资源访问,同时支持实时查询和分析,为企业数据治理和数据资源共享提供高质量的技术保障。
4.数据中台
数据中台是企业的数据能力集中载体,作为核心数据底座,为不同场景下的数据应用需求赋能,推动数字化场景的快速建设。与数据库、数据仓库、数据湖等概念不同,数据中台并非是指某个具体的系统或技术组件,是从“企业能力”的视角提出的一个和数据相关的抽象概念。不同企业在数字化转型实践中,对数据中台有不同的理解,也有差异化的技术选型策略。
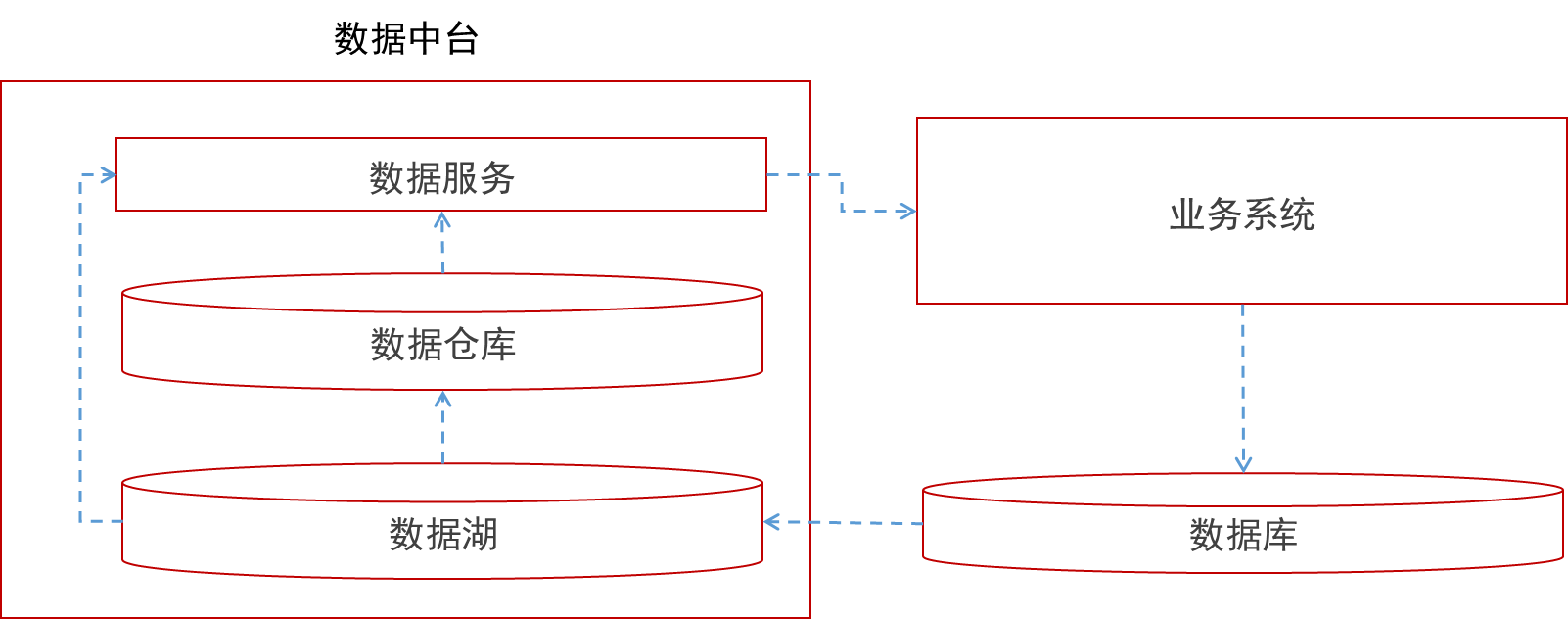
图19. 数据库、数据仓库、数据湖与数据中台的关系
从技术层面看,数据中台等于“数据存储”加“数据服务”两个主要部分。数据存储的部分既可以是数据仓库、也可以是数据湖。一般来说,可以将数据中台的数据仓库部分进行分层划分,在数据加工之前的数据层为“贴源层”,在数据加工之后的数据层为“分析层”。在对数据中台进行管理和维护时,通常需要对从“贴源层”到“分析层”的整个链路进行监控和溯源,保证数据质量的透明、可控,也为上层数据应用建设提供可靠的技术参考。
数据存储上的数据内容,需要通过“服务化”的方式被封装隔离,外界系统以及用户须通过访问服务的方式来访问数据中台上宝贵的数据资源,以此获得企业的核心数据能力。服务,是数据中台区别于一般数据存储载体的重要特点,可以为企业的数据管理和数据应用带来诸多好处,例如:标准化数据处理逻辑;提高数据应用的集成效率;防止原始的数据被滥用或者篡改;提高数据模型和方法可维护性;实现受控的数据访问与应用。

