
 刘国昊
刘国昊
CB(Content-basedRecommendations),即根据用户历史喜欢的内容(Item),为用户推荐与他历史喜欢的内容相似或相关的内容。例如,在汽车资讯场景下,用户读了很多关于“宝马”汽车的文章,那么其列表里也会推荐跟“宝马”汽车相似的文章。值得注意的是,根据内容相似的推荐并不仅指的是标题,而是所有被认为有计算价值的文本的相似性。
计算过程也有以下几个步骤:
Item Representation:特征提取,提取能代表Item的特征;
Data modeling:数据建模,根据文本特征建立用户喜好的语义特征模型;
Recommendation generation:推荐结果生成,根据模型计算出与用户特征语义相似度最高的候选Item。
在语义计算过程中往往会用到长短期记忆算法(Long-Short-Term Memory)——LSTM算法,作为深度学习算法的一种,我们有必要介绍一下深度学习的一些基本背景。
深度学习的历史大体可以分为三个阶段:
一、在20世纪40年代至60年代,当时深度学习被称为控制论;
二、在20世纪80年代至90年代,此期间深度学习被誉为联结学习;
三、从2006年开始才以深度学习这个名字开始复苏(起点是2006年,GeoffreyHinton发现深度置信网可以通过逐层贪心预训练的策略有效地训练)。
而深度学习逐渐成为机器学习的显学还是从2012年Geoffrey E. Hinton的团队在ImageNet比赛(图像识别中规模最大、影响最大的比赛之一)中使用深度学习方法获胜之后。自此,深度学习的研究突飞猛进,不仅是在图像识别领域,在学术界顶级的学术会议中关于深度学习的研究越来越多,如CVPR、ICML等。工业界也贡献了越来越多的计算支持或者框架,如Nivdia的cuda、cuDnn,Google的tensorflow等,为深度学习的研究和发展立下了汗马功劳。而可以预见的是,随着可以使用的训练数据量逐渐增加,深度学习的应用空间必将越来越大;随着计算机硬件和深度学习软件基础架构的改善,深度学习模型的规模必将越来越大。总之,深度学习处于快速发展的快车道上,未来可期。
回到LSTM算法,其是一种特殊的RNN(Recurrent neural network,循环神经网络),RNN是一系列能够处理序列数据的神经网络的总称。RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,LSTM模型作为门限RNN中最著名的一种,被研究人员提出用来解决RNN模型梯度弥散的问题。以下为其单一节点的结构图。如图7–2所示。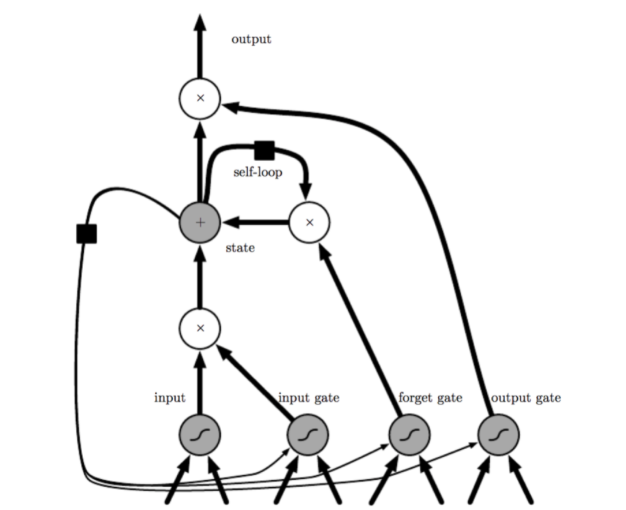
图7-2 LSTM的CELL示意图
在传统的RNN中,训练网络的方法使用的是反向传播算法BPTT(back-propagation through time),当时间比较长时,需要回传的残差呈指数下降,导致网络权重更新缓慢,无法体现RNN的长期记忆效果,因此需要一个存储单元来存储记忆,LSTM模型的思想是将RNN中的每个隐藏单元换成了具有记忆功能的Cell,解决了RNN中的长期依赖问题。关于LSTM模型的技术理论非常庞杂,故不对技术细节进行详述。
在LSTM模型运行过程中,全量的文本通过分词、降维、去噪、文本向量化完成文本的特征抽取。并通过大量的文本的文本特征生成语义模型,一般来说可能会涉及LSI、LDA和Doc2vec这些语义算法(不同文本长度适用不同的语义算法)。所有的文本在语义模型中都可以计算出两两之间的距离(即可以理解为所有的词语都会在600×600维的语义模型中找到一个可被计算机识别的坐标点),那么当用户发生新的用户行为时,所发生行为的内容会根据以上的过程进入语义模型中,并与其他文本进行两两矩阵计算,就计算出了此内容距离最接近的内容文本有哪些,并按照距离(相似度)的远近以相似度权重的形式返回给用户,也就是用户所看到的一篇篇的推荐内容都是根据相似度权重的大小排列进行展示的。如图7–3所示。

图7–3 mongo中的文本分词示意图
在正常的用户行为操作环境中,不仅内容有时间的限制(超过多少天的内容从模型中移除),用户的操作也是有时效性区别的。用户今天看的内容,跟用户前天甚至一个星期前看的内容对于用户当下的需求大小肯定是不一样的。那么,我们该如何处理基于内容推荐的时间问题呢?
为了解决这个问题,我们可以引入一个兴趣衰减机制,即让用户的关键词表中的每个关键词喜好程度都按一定周期保持衰减。考虑不同词的TFIDF值可能存在的差异已经在不同的数量级了,我们考虑用指数衰减的形式来相对进行公平的衰减。即引入一个系数,每隔一段时间,对所有用户的所有关键词喜好程度进行指数级的衰减,那么就完成了模拟用户兴趣迁移的过程。
可以这么说,基于内容的推荐算法几乎是所有的推荐业务场景都会用到的主流算法,但是其无法挖掘用户的潜在兴趣(Over-specialization),如果一个人只看与历史行为有关的文章,那CB只会给他推荐更多与此相关的文章,会让用户进入信息茧房。但其推荐相似结果的特性能帮助用户尽快地聚焦自己的兴趣。这也是大部分用户使用淘宝、使用今日头条,认为有智能推荐体验的主要算法。

