
 刘国昊
刘国昊
推荐系统需要的数据可以用一句话来概括:“哪个用户在什么时间点对什么内容发生了什么行为,这个内容是什么。”如图7–1所示。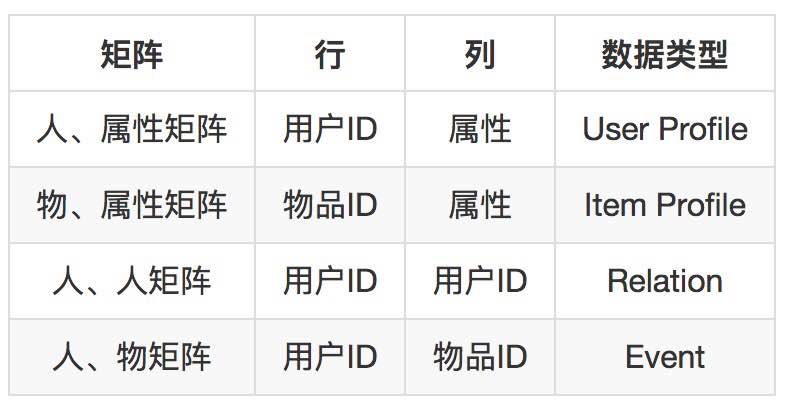
图7–1 推荐系统需要的数据
我们拆分来看,大致可以分为三类数据:
1.物料类数据。也就是内容的文本类数据,如内容的标题、正文、作者、内容来源、标签或关键词、分类(如时政、健康、娱乐等)、发布时间等,在电商场景内还可能会有价格、商品属性、商品复购周期等。不同的业务场景下可能会涉及不同维度的数据,但目前能用作推荐的仅是文本数据。在服务家居和素材类网站客户的过程中,曾经尝试用图像识别的方法做相似度推荐但效果并不理想,反而是在社交网站上用实体命名识别会有作用,当然实体命名识别的载体也是文字。目前的图像识别技术还不能识别图像或者视频中的行为意图,只能识别类似“三个人扭打在一起”等行为描述,而很显然这样的描述特征是不能供推荐系统所用的。
2.用户类数据。用户类数据则包括:
人口统计学数据:性别、年龄、职业等;
兴趣标签类数据:美妆、电影、旅游等;
地理位置数据:经纬度坐标;
特定场景下的静态身份数据:岗位、专业、技能等业务场景下才会需要的身份数据。
我们需要知道的是,虽然用户类数据有很多,但并不是所有的数据都能被推荐系统所需要,往往是特定的业务场景下会用到特定的用户类数据,这个得根据业务场景进行具体分析。如银行理财产品推荐中可能会用到用户的职业、财产收入等数据,而这些数据在新闻场景下是不会用到的。因此,有很多人在引用用户的“用户画像”做推荐,我们认为这是非常错误而且反常识的做法。首先,目前为止,用户画像尚没有平台能做到全维度数据覆盖,也就是画像刻画得有偏差,那么上梁不正下梁歪,整个推荐都会出问题。其次,即使做到了全维度数据覆盖又该如何确认确保“用户画像”标签的粒度呢?标签的设立本质就是用少量的词汇来描述一个人,那么多少角度的多少词汇可能描述完一个人呢?标签的存在就注定了信息量的损失。最后,如果一个人的“用户画像”被刻画为“金领、IT男、月入百万”难道就不会去买9.9元包邮的商品么?很明显,这都是用“用户画像”做推荐反常识、反逻辑的地方,这个后续我们再细讲。
3.用户行为数据。包含了用户对内容发生的行为,如点击、分享、点赞、收藏、加入购物车、浏览时长、播放完毕等根据业务场景制定的能反映用户兴趣的数据,也包含了用户发生行为的时间即用户点击这条内容是在什么时间,用户浏览10s是在什么时间。我们讲求的推荐系统的实时推荐也是依赖用户的行为数据能够毫秒级的上报至推荐系统,这个时间一般控制在50ms以下。而我们有了用户的行为数据之后,则可以得出人与人之间的关系特征。

