
 刘国昊
刘国昊
下面我将分享艾克斯的智能推荐系统技术架构。如图1–2所示。
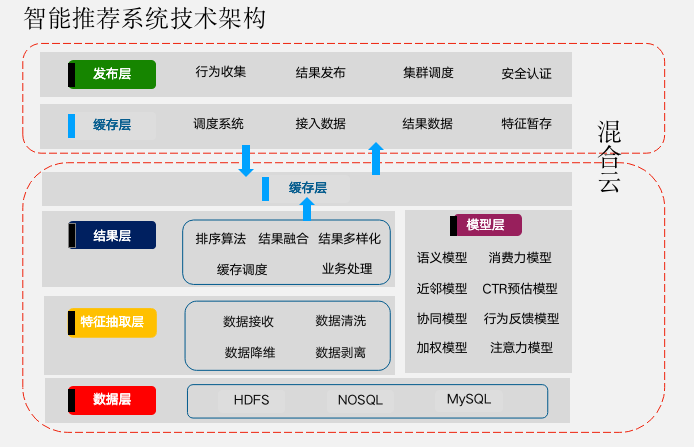
图1–2艾克斯的智能推荐系统技术架构
推荐系统主要是由六个部分组成的,分别是数据层、特征抽取层、模型层、结果层、缓存层和发布层。
数据层主要用来存储用于推荐的数据,包括用户的静态数据、用户的行为数据、物料数据。其中用户的行为数据包括了“用户在什么时间对什么物料发生了什么行为,这个物料是什么”。
特征抽取层主要用来接收、清洗来自数据层上报的数据并进行数据特征抽取,一般来说需要经历文本数据的分词、降维、去噪、向量化,生成能够被模型层用来建立模型的特征向量。
特征抽取层处理过的数据会上报至模型层进行建模,一套成熟、通用的推荐系统模型层一般会包括语义模型、LSTM模型、近邻模型、协同模型、FM模型、GBDT+LR模型、DNN模型、加权模型、用户行为反馈模型等,适配电商业务的模型一般还会有用户消费力模型、召回周期模型等。而具体选择哪套模型,哪几套模型融合做多线路召回,取决业务场景、业务目标、数据特征、计算时间、成本及商业价值目标,根据业务做多模型融合的判断和选择。各套模型将用户的特征向量通过特征-物料相关矩阵转化为初始推荐物品列表。判断一套推荐系统是否灵活,是否能根据业务场景进行实时的调整则要看模型里是否包含加权排序模型,也就是推荐系统的运营者能否通过加权体系实时干预推荐结果的输出。
模型层的模型分为近线与离线计算。
对于近线部分来说,主要目的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地更新在线推荐模型。这样做的好处是用户的最新兴趣能够近乎实时地体现到推荐结果里。
对于离线部分而言,通过对线上用户点击日志的存储和清理,整理离线训练数据,并周期性地更新推荐模型。对于超大规模数据和机器学习模型来说,往往需要高效的分布式机器学习平台来对离线训练进行支持。
结果层主要的作用是对模型层产出的结果进行过滤与排序,过滤主要包括过滤已发生行为的结果、过滤屏蔽的结果、候选物料以外的物料。一般来说,模型层的多个模型会分别输出特定的结果及权重,而结果层则通过排序将结果按照权重或者优先级排列。当有特定业务需求时,结果将根据业务规则生成最终的推荐结果,并上报到缓存层,供前端用户进行调用。举个例子:某电商平台只在推荐列表中推荐净利润为5元以上的产品,且要求利润越高的产品要优先推荐,那么这时结果层就过滤了5元以下的产品,并通过加权模型产生的权重影响了推荐结果的最终排序。
模型层和结果层共同组成了推荐系统的召回和排序阶段。通过召回环节,给用户推荐的物料从数以万计降到数以千计以下的规模。利用排序模型通过粗排的方式进一步减少后续环节传递的物料,再通过较为复杂的排序模型和权重体系对物料进行精准排序。当然,精准排序后的结果往往也不会直接展示给用户,可能还要加上一些业务策略,例如去重已读、推荐多样化等,最后形成推荐结果存放于缓存层。
缓存层主要用于推荐结果的暂存,供用户进行实时的调度。就好像从上游流下的河水都被暂存在了堤坝中。而发布层则作为用户调度使用和用户收集的接口,供平台方在各个业务场景下释放推荐结果。例如农田需要灌溉,就从水库中引一部分水到田中。人们需要喝水,就从水库中引一部分水到自然水厂。若旱季到了,原有的供应量达不到灌溉量,那么农业部门则要求堤坝多放一点水到农田中以保证正常的灌溉。
从推荐系统架构可以窥见,推荐系统涵盖了数据存储、特征抽取、特征计算、推荐结果排序和前端结果调用,其本质是一套基于数据计算的信息分发系统。由于底层数据如用户数据、用户行为数据的不同,其最终调用的结果显然也是不同的,因此这套信息分发系统具备了个性化分发的特性。

